Writing Sums, Products and Integrals in LaTeX
In this blog post, we will learn how to write sums, products, and various types of integrals using LaTeX.

Representing Norms in LaTeX
In this blog post, we will learn how to write the norm function in LaTeX and how to represent different types of norms.

Writing Ceil, Floor and Abs in LaTeX
In this blog post, we will learn how to write the ceiling, floor and absolute value functions in LaTeX, both in mathematical notation and as text.

Simplifying LaTeX Notation with \newcommand
In this blog post, we’ll explore how to define convenient shortcuts using \newcommand in LaTeX, making your notation more concise and readable.

Turbulent flow segmentation with SAM
A simple example demonstrating the use of Meta’s Segment Anything Model (SAM) on a video of turbulent fluid flow.

How to create non-square images with DALL-E 2
The DALL-E API from OpenAI is a very powerful image generation tool. However one limitation is that it only outputs square images. In this tutorial we will learn how to generate images of arbitrary dimension such as portraits and landscapes.

How to generate subtitles with the Whisper API in Python
In this tutorial we will learn how to use the Whisper API to generate subtitles for a video. We will generate subtitles for the opening of A Star Is Born (1937), an early colour movie that has been frequently remade.

Transformer Part 2: Train a Translation Model
In Part 1 of the tutorial we learned how to how build a transformer model. Now it is time to put it into action. There are lots of things we can do with a transformer but we will start off with a machine translation task to translate from Spanish to English.

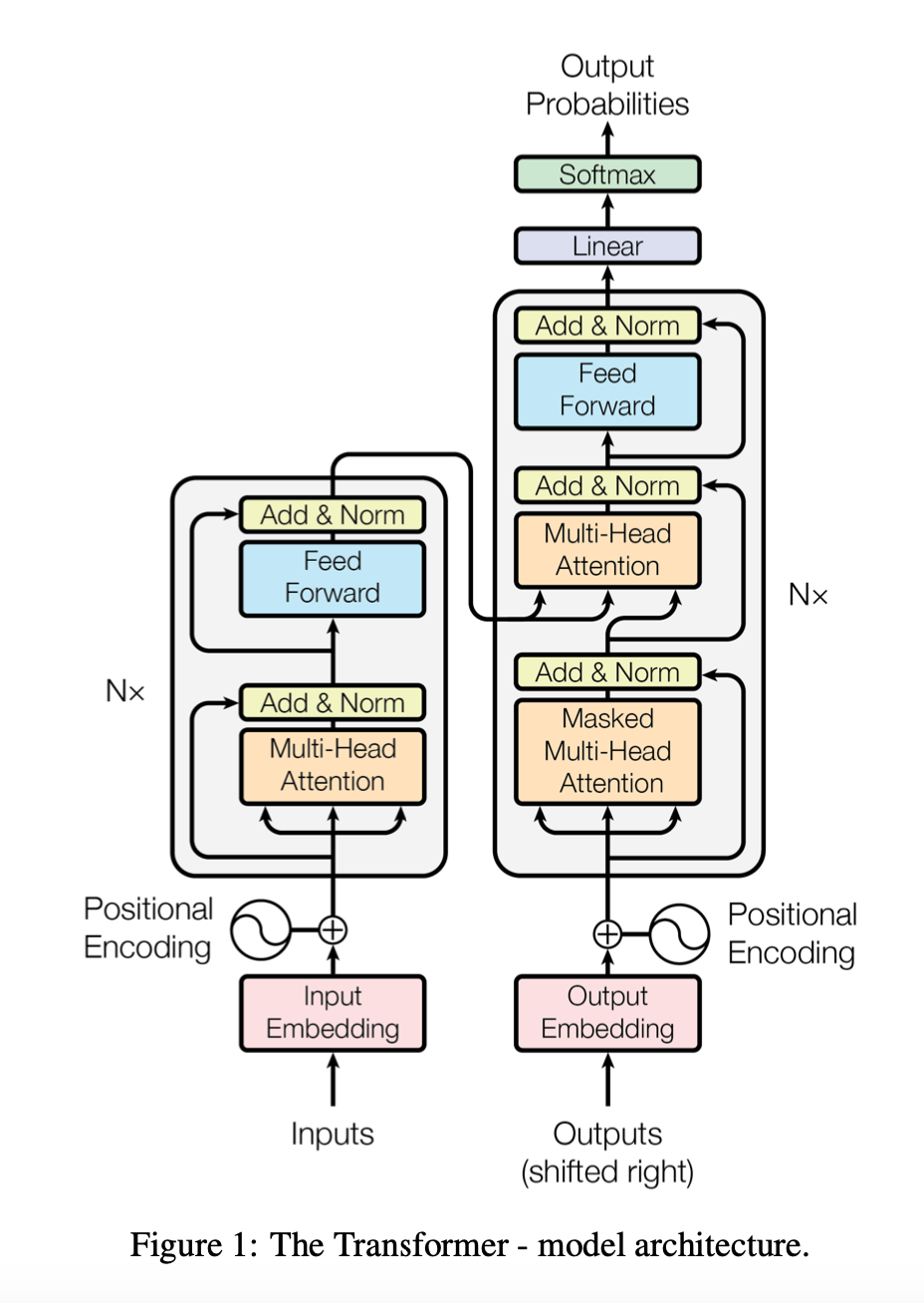
Transformer Part 1: Build
Since its introduction the Transformer architecture has become very influential and has had successes in many tasks not just in NLP but in other areas like vision. This tutorial is inspired by the approach in The Annotated Transformer and uses text directly quoted from the paper to explain the code.
PixelCNN
The PixelRNN family of auto-regressive architectures consists of models that learn to generate images a pixel at a time. In this post we will focus on the PixelCNN model which is based on the same principles but uses convolutional layers instead of recurrent layers. It is simpler to implement and once we have grasped the core concepts, it is straightforward to understand the recurrent versions.
