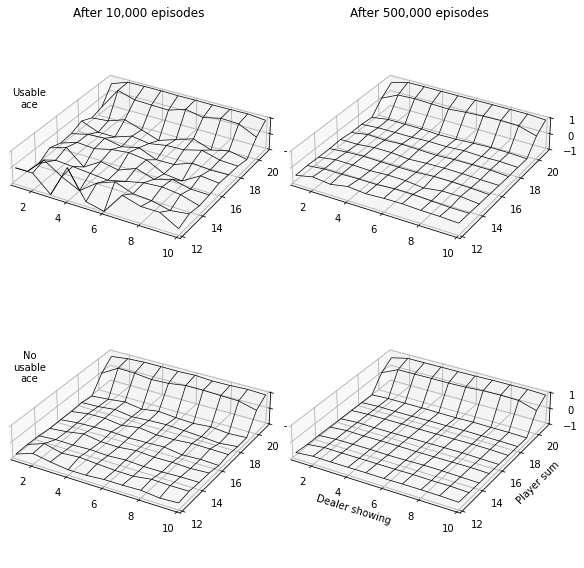
First Visit Monte Carlo Prediction for Blackjack (RL S&B Example 5.1)
In this tutorial we will demonstrate how to implement Example 5.1: Blackjack from Reinforcement Learning (Sutton and Barto).
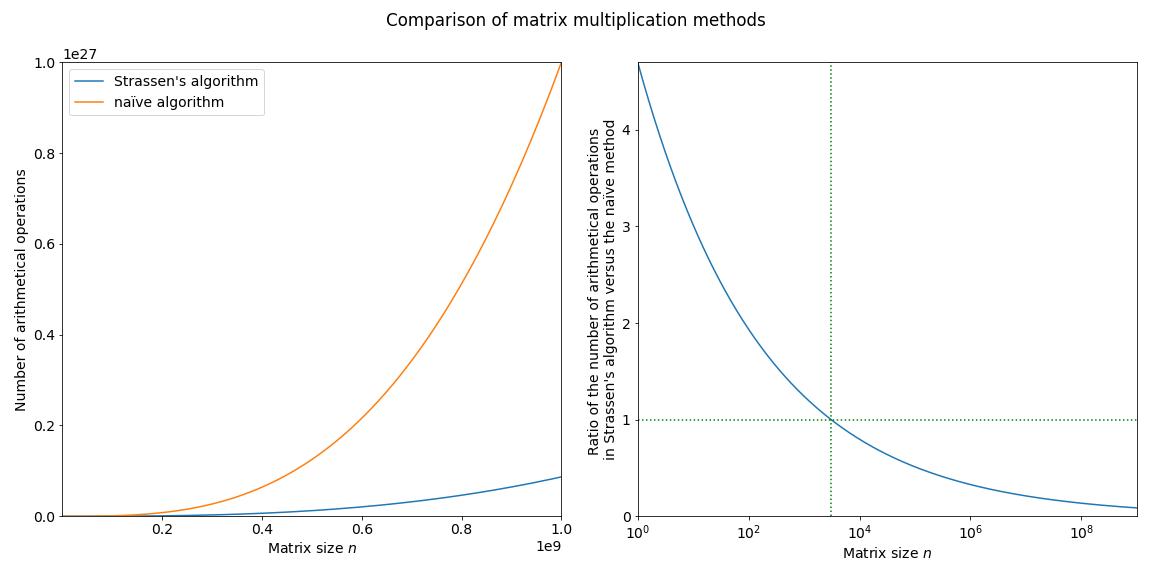
Strassen’s algorithm for matrix multiplication
This is the first of a planned series of blogs covering background topics for DeepMind’s AlphaTensor paper. In this post we will cover Strassen’s algorithm for matrix multiplication.
Implementing the Fréchet Inception distance
A popular metric for evaluating image generation models is the Fréchet Inception Distance (FID). Like the Inception score, it is computed on the embeddings from an Inception model. But unlike the Inception score, it makes use of the true images as well as the generated ones. In the post we will learn how to implement it in PyTorch.

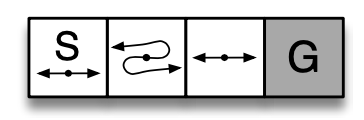
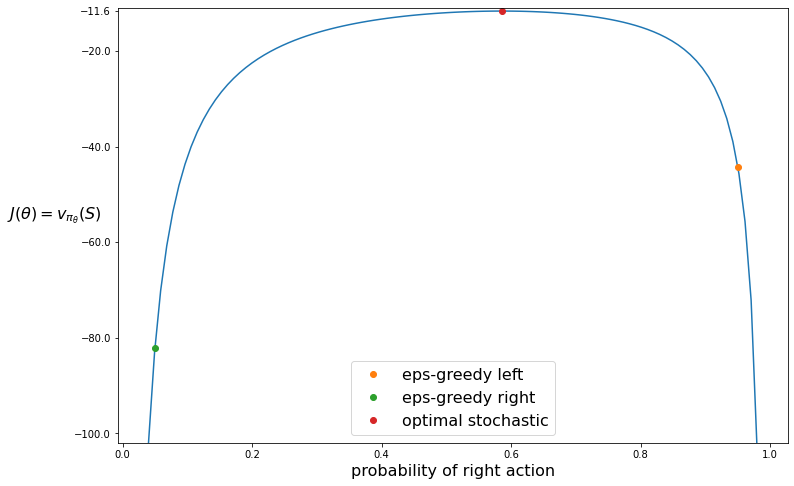
REINFORCE on the short-corridor gridworld, Part 2 (RL S&B Chapter 13)
In the previous post we introducted the short-corridor gridworld with switched actions. We found an analytical solution for the probability for moving right. Now we will use the REINFORCE algorithm to solve this problem.
Speeding Up Diffusion Sampling
An important disadvantage with diffusion models is that a large number forward passes - typically 1000 or more - are needed to generate samples, making inference slow and expensive. In this post we will look at a couple of different methods that have been developed to speed up inference.

An Introduction to Diffusion
In this blog we will learn about the basic diffusion-based generative model introduced in Denoising Diffusion Probabilistic Models (DDPM). This post will cover the basics at a relatively high level but along the way there will be optional exercises that will help you to delve deeper into the mathematical details.

Veg2vec - word embeddings for plant-based foods with health benefits
One of the most exciting uses of machine learning is scientific discovery. Sometimes long before a discovery is officially made people have written about similar ideas and one could speculate what might have happened if some dots had been connected sooner. This is exactly what the mat2vec model (code, paper) seeks to do with the help of AI

A quick overview of GLIDE
You have probably come across DALL-E 2 a large-scale image generation model from OpenAI. If not, you can read about it in their blog. DALL-E 2 uses a class of models known as diffusion models. The DALL-E 2 paper does not go into a lot of detail about the model architecture since it mostly extends an earlier architecture GLIDE. This article provides a brief introduction to the GLIDE architecture.

REINFORCE on the short-corridor gridworld, Part 1 (RL S&B Chapter 13)
In this tutorial we will demonstrate how to implement Example 13.1 of Reinforcement Learning (Sutton and Barto).
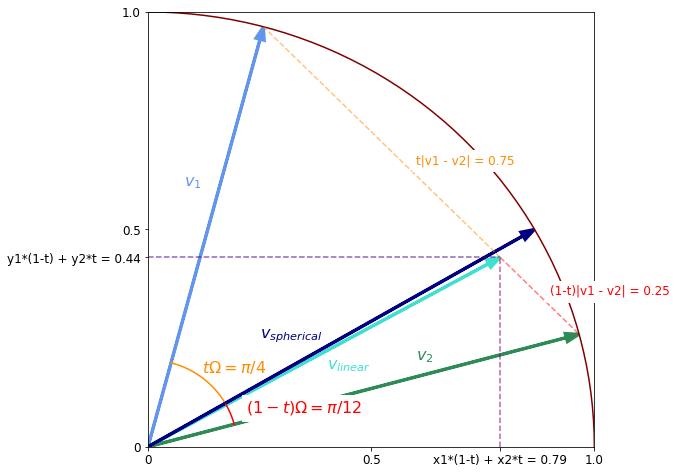
Spherical Interpolation
\(\newcommand{\vv}{\mathbf{v}}\) In machine learning applications you sometimes want to interpolate vectors in a normalised latent space such as when interpolating between two images in a generative model. An appropriate method for doing this is spherical interpolation. In this post we will derive the formula for this method and show how it differs from linear interpolation.